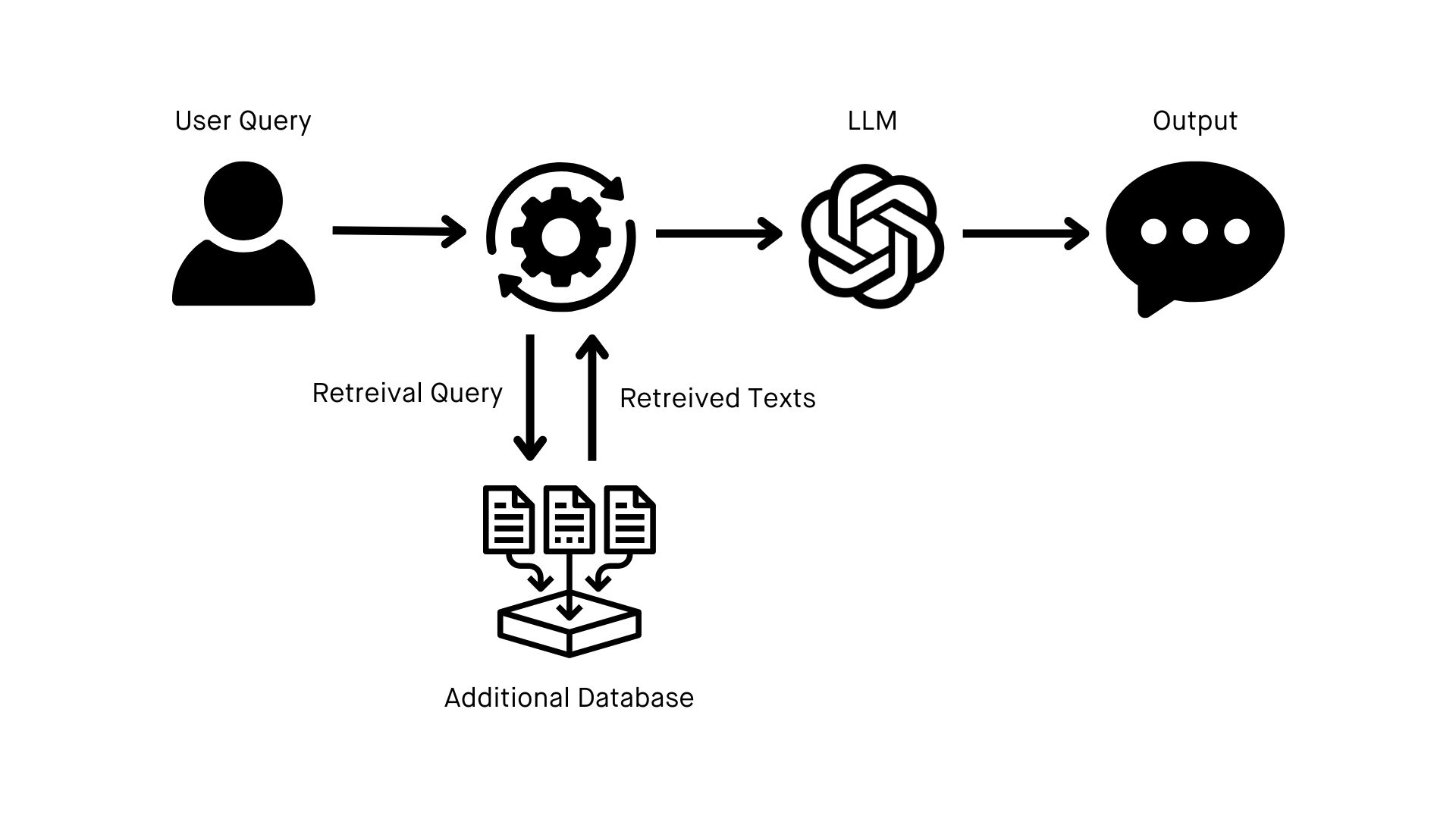
To get started building your own RAG implementation, you’ll need the following ingredients.
Preparing these ingredients will take a matter of months, depending on the complexity of your data and the current state of your architecture. The good news, however, is that this is the most time-consuming part of the process. Once your objectives and data are in order, actually implementing RAG and testing the system takes just a week or two.
Even better, these foundational elements aren’t just crucial steps for RAG, they carry over to virtually every other aspect of your organization’s AI transformation.
A set of clearly defined objectives
With RAG, the more specific you can be with what you want to achieve, the better. Whether it’s improving customer support, creating personalized content, or enhancing data-driven decision-making, knowing when and how you will eventually engage with the system will provide the guidance you need for the duration of the implementation process.
The right LLM
It may seem obvious, but you’ll need to select the LLM that is best suited for your use case and that can be integrated with a retrieval system. You can select an open-source LLM like Mistral or Llama, or a commercially available option like ChatGPT.
Some important factors to consider in your decision are scalability, integration capabilities, cost, and (of course) your set of clearly defined objectives.
A foundation in data engineering
The best way of approaching RAG is by thinking of it as a data engineering exercise. Given the current state of AI, with most organizations in the early stages of their AI transformation, the most significant barrier to using RAG is getting your data organized and structured so that it is compatible with an LLM.
With a foundation in data engineering, the bulk of your RAG implementation work is about building a source for an additional knowledge base that exists upstream within your organization and is populated by a live data set that is continuously updated.
Depending on your objectives, you may also want to consider creating multiple data sources for use across multiple knowledge bases. Having separate knowledge bases for product information and brand guidelines, for example, may help you unlock new applications for your RAG-enabled LLM.